
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- reivew
- 위험관리
- 리눅스마스터2급
- Review
- study
- wargame
- IT
- Shell
- 정보처리기사
- 공부
- 정리
- 워게임
- 보안
- keyword
- 자격증공부
- 드림핵
- 보안용어
- 리눅스
- 클라우드
- webhacking
- Security
- DreamHack
- 자격증
- 기록
- 복습
- 취약점진단
- it자격증
- 케이쉴드주니어
- Linux
- 웹해킹
- Today
- Total
IT Memory Note
[정보처리기사] SQL 응용 : 데이터베이스 기본(2) 본문
1️⃣ 트랜잭션(Transaction)
☆☆☆
(2) DDL(Data Definition Language)
1. 데이터 정의어의 개념
- 데이터를 정의하는 언어로서 '데이터를 담는 그릇을 정의하는 언어'
- 테이블과 같은 데이터 구조를 정의하는 데 사용되는 명령어들로 특정 구조를 생성, 변경, 삭제, 이름을 바꾸는 데이터 구조와 관련된 명령어들을 데이터 정의어라고 부름
2. DDL의 대상
⓵ 스키마(Schema)
㉮ 스키마의 개념
- DB의 구조, 제약조건 등의 정보를 담고 있는 기본적인 구조
- 외부/개념/내부 3 계층으로 구성되어 있음
㉯ 스키마의 구성
| 구성 | 설명 |
| 외부 스키마 (External Schema) |
• 사용자나 개발자의 관점에서 필요로 하는 DB의 논리적 구조 • 사용자 뷰를 나타냄 • 서브 스키마로 불림 |
| 개념 스키마 (Conceptual) |
• DB의 전체적인 논리적 구조 • 전체적인 뷰를 나타냄 • 개체 간의 관계, 제약조건, 접근권한, 무결성, 보안에 대해 정의 |
| 내부 스키마 (Internal Schema) |
• 물리적 저장장치의 관점에서 보는 DB 구조 • 실제로 DB에 저장될 레코드의 형식을 정의하고 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 표현 |

⓶ 테이블(Table)
㉮ 테이블의 개념
- 데이터를 저장하는 항목인 필드(Field)들로 구성된 데이터의 집합체
- 하나의 DB 내에 여러 개의 테이블로 구성될 수 있고, 릴레이션(Relation) 혹은 엔터티(Entity)라고도 불림
㉯ 테이블의 용어

| 용어 | 설명 |
| 튜플(Tuple) / 행(Row) | • 테이블 내의 행으로 레코드(Record)라고도 함 • 테이블에서 같은 값을 가질 수 없음 |
| 속성(Attribute) / 열(Column) | 테이블 내의 열 |
| 카디널리티(Cardinality) | 튜플(Tuple)의 개수 |
| 차수(Degree) | 속성(Attribute)의 개수 |
| 도메인(Domain) | 하나의 속성이 취할 수 있는 같은 타입의 원자값들의 집합 |
⓷ 뷰(View)
㉮ 뷰의 개념
- 논리 테이블로서 사용자에게(생성 관점 아닌 사용 관점에서) 테이블과 동일함
- 아래 그림에서 '테이블 A'와 '테이블 B'는 물리 테이블이고, '뷰 C'는 2개의 테이블을 이용하여 생성한 뷰임
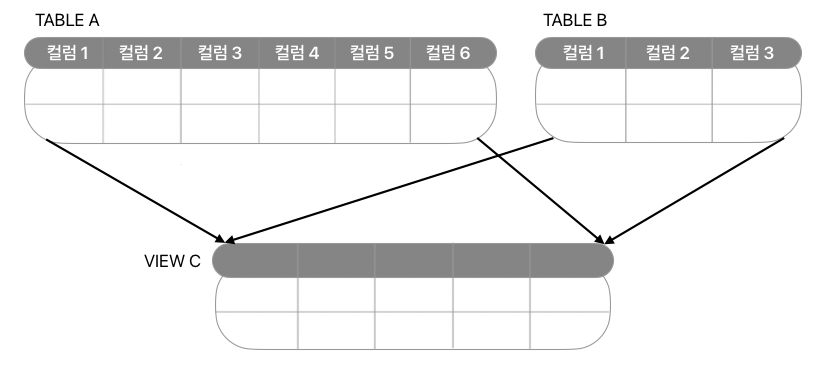
- 뷰는 '테이블 A'와 같은 하나의 물리 테이블로부터 생성 가능하며, 다수의 테이블 또는 다른 뷰를 이용해 만들 수 있음
- 뷰와 같은 결과를 만들기 위해 조인 기능을 활용할 수 있으나, 뷰가 만들어져 있다면 사용자는 조인 없이 하나의 테이블을 대상으로 하는 단순한 질의어를 사용할 수 있음
㉯ 뷰의 장단점
| 구분 | 장단점 | 설명 |
| 장점 | 논리적 독립성 제공 | DB에 영향을 주지 않고 애플리케이션이 원하는 형태로 데이터에 접근 가능 |
| 데이터 조작 연산 간소화 | • 애플리케이션이 원하는 형태의 논리적 구조를 형성하여 데이터 조작 연산을 간소화 • 복수 테이블에 존재하는 여러 종료의 데이터에 대해 단순한 질의어 사용이 가능  |
|
| 보안 기능(접근제어) 제공 | • 특정 필드만을 선택해 뷰를 생성할 경우 애플리케이션은 선택되지 않은 필드의 조회 및 접근 불가 • 중요 보안 데이터를 저장 중인 테이블이나 컬럼에는 접근 불허 |
|
| 단점 | 뷰 자체 인덱스 불가 | 인덱스는 물리적으로 저장된 데이터를 대상으로 하기에 논리적 구성인 뷰 자체는 인덱스를 가지지 못함 |
| 뷰 변경 불가 | • 뷰의 정의를 변경하려면 뷰를 삭제하고 재생성 • 뷰 정의는 ALTER 문을 이용하여 변경할 수 없음(뷰는 CREATE 문을 사용하여 정의, 뷰를 제거할 때에는 DROP 문을 사용) |
|
| 데이터 변경 제약 존재 | 뷰의 내용에 대한 삽입, 삭제, 변경 제약이 있음 |
⓸ 인덱스(Index)
㉮ 인덱스의 개념
- 검색 연산의 최적화를 위해 DB 내 값에 대한 주소 정보로 구성된 데이터 구조
- 데이터를 빠르게 찾을 수 있는 수단으로써, 테이블에 대한 조회 속도를 높여 주는 자료 구조
- 테이블의 특정 레코드 위치를 알려주는 용도로 사용함
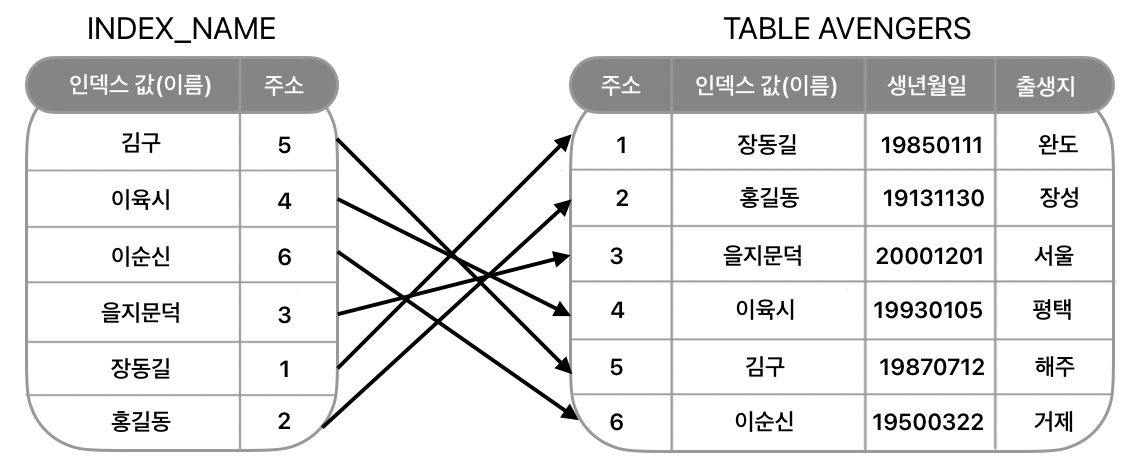
※ DB 파일 구조
| 파일 구조 | 설명 |
| 순차 방법 | 레코드들의 물리적 순서가 레코드들의 논리적 순서와 길게 순차적으로 저장하는 방법 |
| 인덱스 방법 | 인덱스가 가리키는 주소를 따라 원하는 레코드에 접근할 수 있도록 하는 방법 → <키 값, 주소>의 쌍으로 구성 |
| 해싱 방법 | 키 값을 해시 함수에 대입시켜 계산한 결과를 주소로 사용하여 레코드에 접근할 수 있게 하는 방법 |
㉯ 인덱스의 특징
- 기본 키(PK) 컴럼은 자동으로 인덱스가 생성됨
- 연월일이나 이름을 기준으로 하는 인덱스는 자동으로 생성되지 않음
- 테이블의 컬럼에 인덱스가 없는 경우, 테이블의 전체 내용을 검색함
- 인덱스가 생성되어 있을 때, 데이터를 빠르게 찾을 수 있음(인덱스 범위 캔 : Index Range Scan)
- 조건절에 '='로 비교되는 컬럼은 대상으로 인덱스를 생성하면 검색 속도를 높일 수 있음
3. DDL의 명령어
| 구분 | DDL 명령어 | 설명 |
| 생성 | CREATE | DB 오브젝트를 생성하는 명령어 |
| 수정 | ALTER | DB 오브젝트를 변경하는 명령어 |
| 삭제 | DROP | DB 오브젝트를 삭제하는 명령어 |
| TRUNCATE | DB 오브젝트 내용을 삭제하는 명령어 |
4. TABLE 관련 DDL
⓵ CREATE TABLE : 테이블을 생성하는 명령어
- CREATE TABLE에서 하나의 컬럼(속성)에 대해 '컬럼명 데이터타입 제약조건'으로 구성됨
< CREATE TABLE 기본 문법(ISO/IEC 9075 기준) >
CREATE TABLE 테이블명(
컬럼명 데이터타입 [DEFAULT 값][NOT NULL]
[, PRIMARY KEY(기본키, ...)]
[, UNIQUE(컬럼명, ...)]
[, FOREIGN KEY(외래키, ...) REFERENCES 참조테이블(기본키)
[, CONSTRAINT 제약조건명 CHECK(조건식)]
);| 제약조건 | 설명 |
| PRIMARY KEY | • 테이블의 기본키를 정의 • 유일하게 테이블의 각 행을 식별 |
| FOREGIN KEY | • 테이블의 외래키를 정의 • 참조 대상을 테이블(컬럼명)로 명시 • 열과 참조된 테이블의 열 사이의 외래키 관계를 적용하고 설정 |
| UNIQUE | 테이블 내에서 얻은 유일한 값을 갖도록 하는 제약조건 |
| NOT NULL | 해당 컬럼은 NULL 값을 포함하지 않도록 하는 제약조건 |
| CHECK | • 개발자가 정의하는 제약조건 • 참(TRUE)이어야 하는 조건을 지정 |
| DEFAULT | 데이터를 INSERT할 때 해당 컬럼의 값을 넣지 않는 경우 기본값으로 설정해주는 제약조건 |
⓶ ALTER TABLE : 테이블을 수정하는 명령어
㉮ ALTER TABLE 컬럼 추가 : 테이블에 필요한 컬럼을 추가하는 문법
- CREATE TABLE의 컬럼에 사용되는 제약조건인 PRIMARY KEY, FOREIGN KEY, UNIQUE, NOT NULL, CHECK, DEFAULT를 ALTER TABLE에서도 사용할 수 있음
< ALTER TABLE 컬럼 추가 문법 >
ALTER TABLE 테이블명 ADD 컬럼명 데이터타입 [제약조건];
㉯ ALTER TABLE 컬럼 수정 : 테이블에 필요한 컬럼을 수정하는 문법
- 테이블 생성을 위한 CREATE 문에 제약조건을 명시 후에 ALTER를 통해 테이블 제약조건의 변경이 가능함
< ALTER TABLE 컬럼 수정 문법 >
ALTER TABLE 테이블명 ALTER 컬럼명 데이터타입 [제약조건];
㉰ ALTER TABLE 컬럼 삭제 : 테이블에 필요한 컬럼을 삭제하는 문법
< ALTER TABLE 컬럼 삭제 문법 >
ALTER TABLE 테이블명 DROP COLUMN 컬럼명;| 옵션 | 설명 |
| CASCADE | 참조하는 테이블까지 연쇄적으로 제거하는 옵션 |
| RESTRICT | 다른 테이블이 삭제할 테이블을 찹조 중이면 제거하지 않는 옵션 |
- CASCADE와 RESTRICT의 경우 외래키(FOREIGN KEY)가 걸려 있을 때 해당함
⓷ TRUNCATE TABLE : 테이블 내의 데이터들을 삭제하는 명령
< TRUNCATE TABKE 문법 >
TRUNCATE TABLE 테이블명;
5. VIEW 관련 DDL
⓵ CREATE VIEW : 뷰를 생성하는 명령어
< CREATE VIEW 문법 >
CREATE VIEW 뷰이름 AS 조회쿼리;- VIEW 테이블의 SELECT 문에는 UNION이나 ORDER BY 절을 사용할 수 없음
- 컬럼명을 기술하지 않으면 SELECT 문의 컬럼명이 자동으로 사용됨
※ UNION : 집합 연산자로 중복행이 제거된 쿼리 결과 집합
※ ORDER BY : 속성값을 정렬하고자할 때 사용함(ASC : 오름차순, DESC : 내림차순, ASC/DESC 키워드 생략 시 오름차순 정렬)
⓶ CREATE OR REPLACE VIEW : 뷰를 교체하는 명령어
- OR REPLACE라는 키워드를 추가하는 것을 제외하고는 CREATE VIEW와 사용 방법이 동일함
< CREATE OR REPLACE VIEW 기본 문법 >
CREATE OR REPLACE VIEW 뷰이름 AS 조회쿼리;※ VIEW는 수정(ALTER)할 수 없어 삭제(DROP) 후에 다시 생성(CREATE)하거나, CREATE OR REPLACE VIEW 명령을 통해 기본의 뷰를 교체해야 함
⓷ DROP VIEW : 뷰를 삭제하는 명령어
< DROP VIEW 기본 문법 >
DROP VIEW 뷰이름;
6. INDEX 관련 DDL
⓵ CREATE INDEX : 인덱스를 생성하는 명령어
- UNIQUE는 생략 가능하고, 인덱스 걸린 컬럼에 중복값을 허용하지 않음
- 복수 컬럼을 인덱스로 걸 수 있음
< CREATE INDEX 문법 >
CREATE [UNIQUE] INDEX 인덱스명 ON 테이블명(컬럼명1, 컬럼명2, ...);
⓶ ALTER INDEX : 인덱스를 수정하는 명령어
- 일부 DBMS는 ALTER INDEX를 제공하지 않음
- 기존 인덱스를 삭제하고 신규 인덱스를 생성하는 방식으로 사용을 권고함
< ALTER INDEX 문법 >
ALTER [UNIQUE] 인덱스명 ON 테이블명(컬럼명1, 컬럼명2, ...);
⓷ DROP VIEW : 인덱스를 삭제하는 명령어
< DROP VIEW 문법 >
DROP VIEW 인덱스명;
'자격증 > 정보처리기사' 카테고리의 다른 글
| [정보처리기사] SQL 응용 : 데이터베이스 기본(4) (0) | 2024.08.21 |
|---|---|
| [정보처리기사] SQL 응용 : 데이터베이스 기본(3) (1) | 2024.08.20 |
| [정보처리기사] SQL 응용 : 데이터베이스 기본(1) (0) | 2024.08.18 |
| [정보처리기사] 프로그래밍 언어 활용 : 파이썬(3) (0) | 2024.08.14 |
| [정보처리기사] 프로그래밍 언어 활용 : 파이썬(2) (0) | 2024.08.14 |



